
The surprisingly high cost of static-lifetime constructors
I was looking at HyperRogue again this week (see my previous post).
It has a really nice localization framework: every message in the game can be translated just
by adding a lookup entry to a single file (like, for the Czech translation, you add entries
to language-cz.cpp); and then during the build process, all the language-??.cpp files
are collated together and used to produce a single language-data.cpp file with a lookup table
from each English message to the same message in every other language. (Seeing all the messages
at once allows us to report on how “complete” each translation is, relative to the others.)
The other day I noticed that this build step — the compilation of langen.cpp, which #includes
language-??.cpp — was taking about 12 seconds, which seemed ridiculously long. So I went looking
into it, and managed to
get the compile time back down
to about 3 seconds. The huge slowdown was because of six functions (one per supported language)
which looked essentially like this:
using Map = std::map<std::string, std::string>;
Map czech_strings;
void langCZ() {
#define X(a,b) czech_strings.emplace(a, b);
#include "language-cz.cpp"
#undef X
}
The X macro here is… an X-macro.
Super useful concept. I recommend X-macros very highly.
Since language-cz.cpp contains about 2000 Xs, what we end up with is a single function that
contains 2000 consecutive calls to std::map::emplace. LLVM really does not like to codegen
such a large function, even at -O0.
So I tried rewriting the langCZ() function into a single statement. That should produce less codegen,
right?
void langCZ() {
czech_strings = Map{
#define X(a,b) {a, b},
#include "language-cz.cpp"
#undef X
};
}
No change!
This is because the expression
std::map<std::string, std::string>{
{"a", "b"},
{"c", "d"},
}
secretly involves a std::initializer_list object. That is, overload resolution chooses
the constructor map(std::initializer_list<Map::value_type>), where Map::value_type is a typedef for
std::pair<const std::string, std::string>. So what this actually generates is the equivalent
of
static std::initializer_list<std::pair<const std::string, std::string>> dummy {
{"a", "b"},
{"c", "d"},
};
czech_strings = Map(dummy);
And that involves a non-trivial object with static storage duration! So the compiler generates
a bunch of code (surrounded by a guard to make it thread-safe) to create std::string("a"),
std::string("b"), and so on. And all those calls to string’s constructor end up being
just as bad for LLVM’s code generator as the calls to emplace that we started with!
To actually eliminate the code, and make LLVM run fast again, we have to make sure that our big chunk of data is completely constexpr-evaluable, so that it won’t generate any instructions for LLVM to choke on. That is, we need something like this:
void langCZ() {
std::pair<const char *, const char *> dummy[] = {
#define X(a,b) {a, b},
#include "language-cz.cpp"
#undef X
};
czech_strings = Map(std::begin(dummy), std::end(dummy));
}
The difference here is that our big chunk of static-lifetime data is all const char *,
not std::string — so the compiler doesn’t need to generate any instructions corresponding
to all those string constructors. The same number of calls to string’s constructor will
happen at run-time, but now they’re happening in a loop inside the range constructor
of std::map.
I wrote a little benchmark
comparing different ways of initializing a std::vector<std::string>.
Here’s the result:
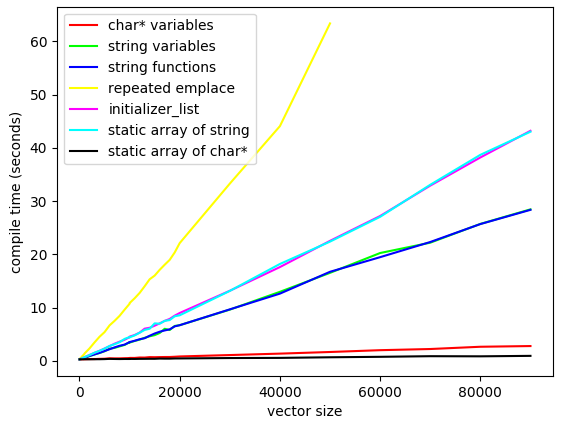
The Y-axis is seconds of compile time for clang++ -std=c++11 -O0 -c; the X-axis is the size of
our input (like, the number that was about 2000 in the HyperRogue case).
Near the bottom of the graph, the red line represents programs of the following form. This represents “no code”; we’re paying for a bunch of linker symbols and that’s all.
const char *s1 = "1";
const char *s2 = "2";
const char *s3 = "3";
The green line in the middle represents programs of the following form.
This represents the extra overhead of codegenning all those calls to std::string’s constructor.
(Not the runtime cost — the compile-time cost of forcing LLVM to crunch through all those instructions!)
std::string s1 = "1";
std::string s2 = "2";
std::string s3 = "3";
The case above causes LLVM to codegen a single massive function with all n of the initializations,
which will be called the first time the translation unit is entered. For comparison, I also tested
programs of the following form, which causes LLVM to codegen n tiny little functions.
The blue line represents these programs. You can see there’s basically no difference between the
green line and the blue line.
std::string f1() { return "1"; }
std::string f2() { return "2"; }
std::string f3() { return "3"; }
Now for the yellow line shooting upward at the top of the graph. It represents programs of the following form, which is essentially the original HyperRogue case.
std::vector<std::string> foo() {
std::vector<std::string> result;
result.emplace_back("1");
result.emplace_back("2");
result.emplace_back("3");
return result;
}
The magenta line represents programs of the following form, using that secret static object of type
std::initializer_list<std::string>. It’s an improvement over the yellow line, but it’s far from efficient.
std::vector<std::string> foo() {
return {
"1", "2", "3",
};
}
The light cyan line overlapping the magenta line shows that if we naïvely rewrite the program to use an
explicit static array of std::string, instead of initializer_list, absolutely nothing
changes on the performance chart:
std::vector<std::string> foo() {
static std::string a[] = {
"1", "2", "3",
};
return std::vector<std::string>(a, a+3);
}
Finally, the black line all the way at the bottom of the graph represents programs of the
following form. This source code looks exactly the same as the code above, but it makes sure
to use const char * for our bulk data instead of std::string:
std::vector<std::string> foo() {
const char *a[] = {
"1", "2", "3",
};
return std::vector<std::string>(a, a+3);
}
You can see it’s even faster than the red line representing a bunch of individual
const char * variables — because we’re not paying for any additional code, and we’re not
paying for all those linker symbols that the red line was paying for.
Conclusion: Avoid any use of X-macros that results in lots of static-lifetime data
with non-trivial construction (or destruction) semantics. And remember that any use of
initializer_list<T> also implicitly creates static-lifetime data of type T!
If you are already in that situation, try to refactor your X-macros to make your static-lifetime data trivial and to move the work into a runtime loop (such as a constructor taking an iterator range). You might see your compile time improve dramatically!
For more on the pitfalls of std::initializer_list, I highly recommend Jason Turner’s
talk from C++Now 2018,
“Initializer Lists are Broken — Let’s Fix Them.”