
A compile-time benchmark for enable_if and requires
enable_if and requiresA lot of templates in the C++ standard library are specified with Constraints: elements,
which means that the library vendor must ensure that they drop out of overload resolution
when their constraints are not met — but the Standard does not mandate any particular
mechanism by which the vendor must implement that dropping-out. Two possible mechanisms are
SFINAE using std::enable_if, and adding C++20 constraints using the requires keyword.
libc++ used to use std::enable_if all over the place; but back in 2019 Eric Fiselier
switched libc++ from the standard enable_if to a slightly different technique:
template<bool B> struct _MetaBase {};
template<bool B> struct _MetaBase<true> {
template<class T> using _Type = T;
};
template<bool B, class T = void>
using _EnableIf = typename _MetaBase<B>::template _Type<T>;
Notice that the standard enable_if_t instantiates a brand-new struct type enable_if<Bn,Tn>
for each of the different Tns you use it with; whereas _EnableIf only ever instantiates
two structs — _MetaBase<true> and _MetaBase<false>. Everything else is done via type aliases,
which according to the
Rule of Chiel
are supposed to be relatively cheaper.
See “SCARY metafunctions” (2018-07-09).
In C++20, it’s tempting to start using Concepts requires-clauses instead of
any version of enable_if. However, are requires-clauses any faster than the old way?
And was that _EnableIf rewrite actually providing any performance benefit? I decided to find out.
The average C++ program doesn’t mess around with constrained templates nearly enough to register
on a compile-time benchmark, so I wrote a Python script (here)
to generate translation units that stress enable_if in particular. I’d previously done something
similar for “Don’t blindly prefer emplace_back to push_back”
(2021-03-03).
My generator produces translation units that look like this:
template<int N> requires (N==0) auto f(priority_tag<0>) -> A<0>;
template<int N> requires (N==1) auto f(priority_tag<1>) -> A<1>;
template<int N> requires (N==2) auto f(priority_tag<2>) -> A<2>;
void test() {
f<0>(priority_tag<3>{});
f<1>(priority_tag<3>{});
f<2>(priority_tag<3>{});
}
except that it varies the number of overloads. (Shown: N=3. The actual number of overloads in my benchmark varied from N=15 up to N=410.) The generator also varies the style of SFINAE in four ways:
template<int N> requires (N==42)
auto f(priority_tag<42>) -> A<42>;
template<int N>
auto f(priority_tag<42>) -> enable_if_t<N==42, A<42>>;
template<int N, class = enable_if_t<N==42>>
auto f(priority_tag<42>) -> A<42>;
template<int N, enable_if_t<N==42, int> = 0>
auto f(priority_tag<42>) -> A<42>;
For the three non-requires versions, we have two different options for how to
implement enable_if_t: the standard way via enable_if<B,T>::type,
and the SCARY way via _MetaBase<B>::_Type<T>. And for each of those we
have one more choice: Do we use the primary template for B=false
and make a custom specialization for B=true, or vice versa?
So that gives us 13 different ways to implement our SFINAE. Let’s time the compilation of each of these translation units and see if any particular way outperforms the others.
Benchmark results
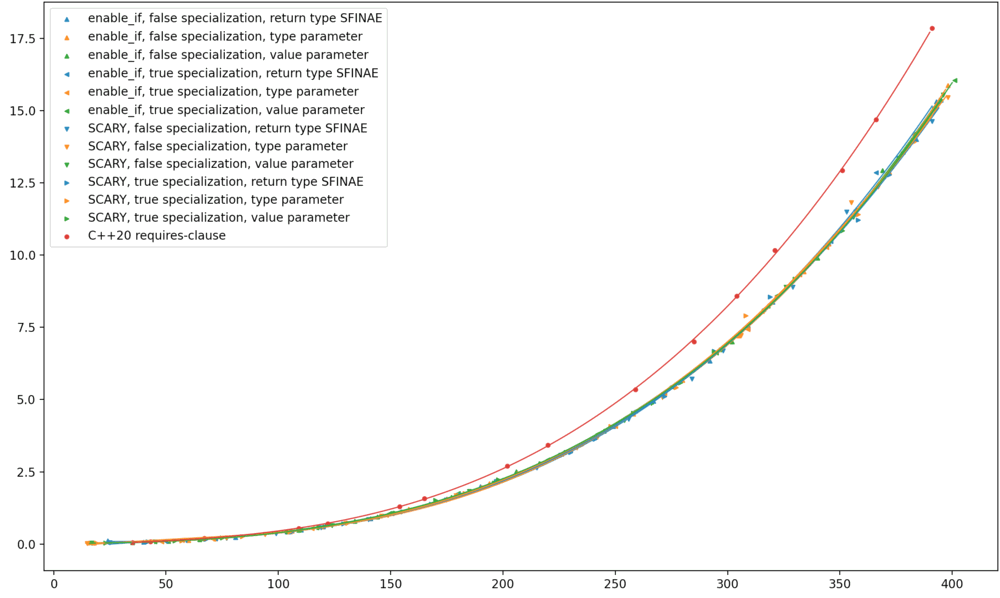
Here’s Clang trunk (the future Clang 14), running on my MacBook. The best-fit curves shown here are quartics, and it’s pretty amazing how exactly they fit the data.
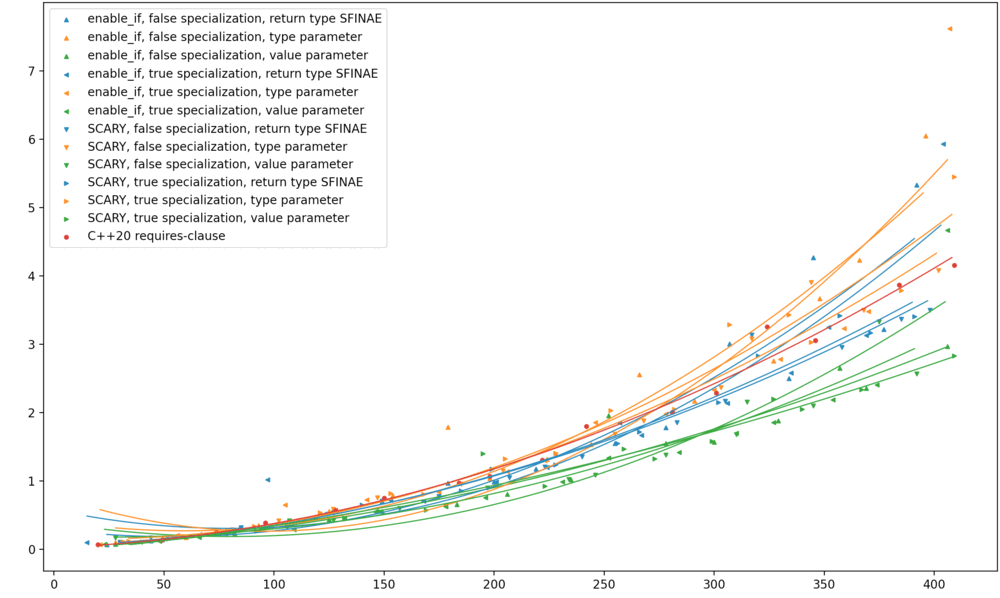
Here’s GCC 10.3, running on RHEL 7.1. This data is much noisier, perhaps because the machine is shared. The best-fit curves here are merely quadratics, because the best-fit quartics ended up super wiggly.
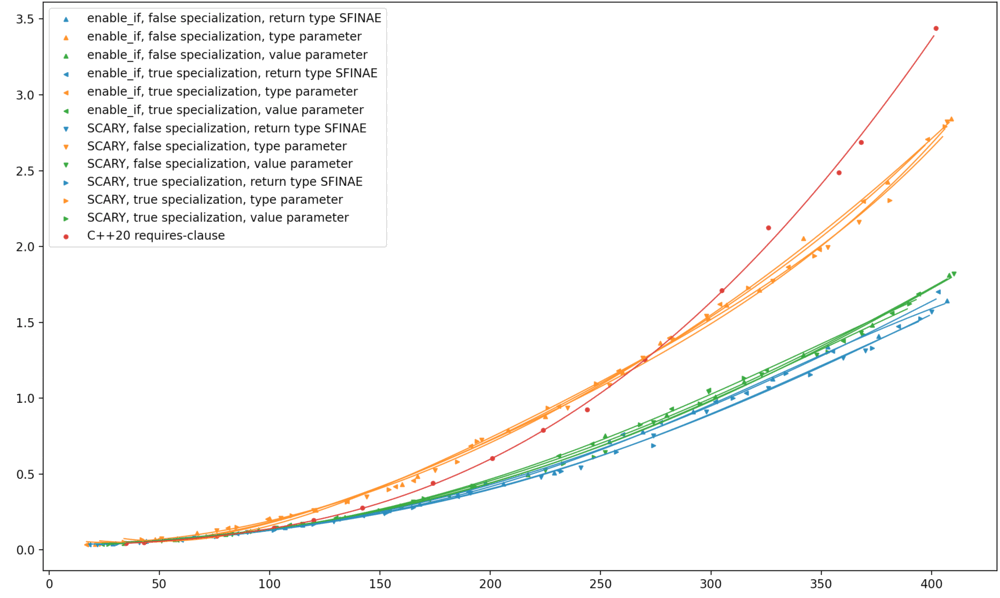
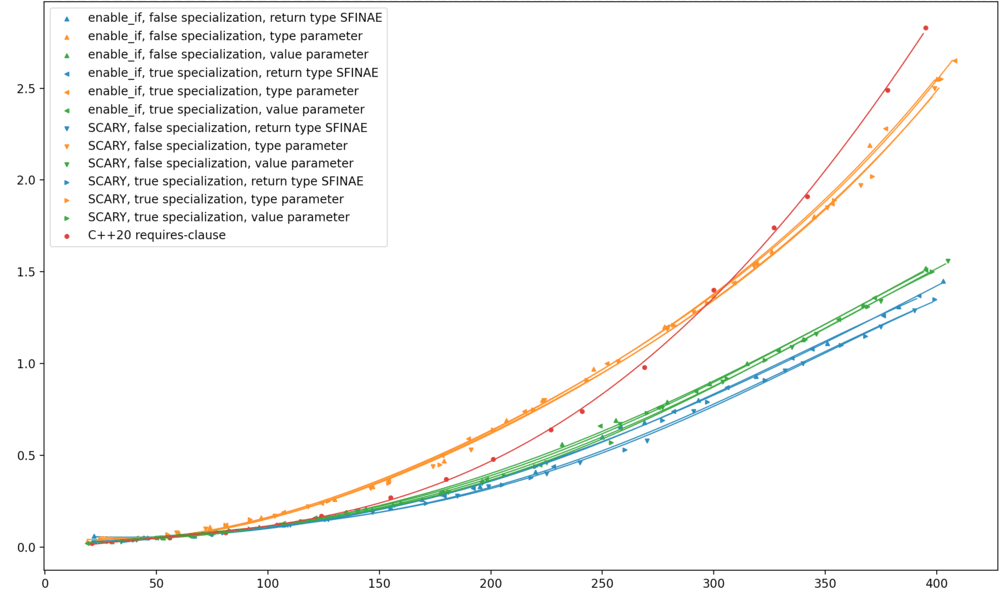
I don’t have the ability to run this benchmark on MSVC, but two intrepid readers
have already sent in their benchmark results! The left graph (from Ilya) shows
MSVC 19.30.30401. The right graph (from Nick Powell) shows MSVC 19.30.30423.
 |
 |
Again I’m amazed how precisely these two sets of curves, generated on different machines, match up. Notice that the individual data points are in different places: my script adds some random “jiggle” to the number of overloads so the results don’t end up as a series of illegible vertical streaks. Also, Ilya’s numbers come from a Core i7 and Nick’s from a Ryzen 5800x; thus the Y-axis timings are slightly different. And yet the shapes of the best-fit curves are pretty much identical between the two graphs!
I observe the following:
-
On Clang, C++20
requiresis significantly worse than the rest. -
On GCC 10.3, the extra-value-parameter method is significantly better than the rest.
-
On MSVC, the extra-type-parameter method seems worse than the other two SFINAE methods, and C++20
requiresseems to be operating on a different polynomial from the rest.
I have no particular explanation for any of these observations.
I should emphasize that these results pertain to a benchmark where
all it does is compute candidate sets, on overload sets with tens to hundreds of non-viable
candidates. Real-world C++ code doesn’t do this. (Code that uses << for output can definitely
run into hundred-candidate overload sets, but even there, we’re not eliminating them via SFINAE.)
So while I hope this benchmark is a cause for mild agitation among C++20 compiler implementors,
in the average C++ codebase I don’t think it indicates any need to avoid requires or even
to prefer one kind of SFINAE over another.
To run the benchmark on your own machine, get my Python script here.
See also: