
A compile-time benchmark for enable_if and requires, part 2
enable_if and requires, part 2Previously on this blog:
Cameron DaCamara and Xiang Fan, of the MSVC engineering team, write in with this insight:
[…It seems that] the primary overhead in MSVC is not actually the requires-clause evaluation itself, but rather the time taken to specialize a primary template [that is,
f] with an explicit template argument. In MSVC, when an explicit template argument is used, the compiler undergoes a separate (partial) type replacement to specialize that template. This happens before deduction and specialization; so the compiler will end up performing that type replacement twice. […]
My original generator produced translation units that looked like this:
template<int N> requires (N==0) auto f(priority_tag<0>) -> A<0>;
template<int N> requires (N==1) auto f(priority_tag<1>) -> A<1>;
template<int N> requires (N==2) auto f(priority_tag<2>) -> A<2>;
void test() {
f<0>(priority_tag<3>{});
f<1>(priority_tag<3>{});
f<2>(priority_tag<3>{});
}
Cameron asked that I see what happens if we stop explicitly specializing f and instead
rely on template argument deduction. That is, let’s produce TUs like this instead:
template<int N> requires (N==0) auto f(index_constant<N>, priority_tag<0>) -> A<0>;
template<int N> requires (N==1) auto f(index_constant<N>, priority_tag<1>) -> A<1>;
template<int N> requires (N==2) auto f(index_constant<N>, priority_tag<2>) -> A<2>;
void test() {
f(index_constant<0>{}, priority_tag<3>{});
f(index_constant<1>{}, priority_tag<3>{});
f(index_constant<2>{}, priority_tag<3>{});
}
Sidebar: The original suggestion
Actually, Cameron suggested a different source transformation; he suggested that we produce TUs like this:
template<int N> requires (N==0) auto f(priority_tag<N>) -> A<0>;
template<int N> requires (N==1) auto f(priority_tag<N>) -> A<1>;
template<int N> requires (N==2) auto f(priority_tag<N>) -> A<2>;
void test() {
f(priority_tag<0>{});
f(priority_tag<1>{});
f(priority_tag<2>{});
}
On MSVC, this benchmark produces really good numbers for requires,
handily beating the other SFINAE approaches.
However, I couldn’t wrap my head around that transformation: was it
really testing the same number of overloads as my original benchmark?
Notice that priority_tag<K+1> is convertible to more things than
priority_tag<K> is, so this version’s test() has a “triangular” feel
to it whereas the original benchmark’s test() was more “square.”
Indeed, Clang runs Cameron’s suggested benchmark in about half the time
of the original.
I decided that if the goal was just to get rid of the explicit template argument,
the “simplest” way to do that was to deduce it from a completely new function
argument. All I’ve done, in the version I picked, is to replace our explicit
f<K>(...) with a deduced f(index_constant<K>{}, ...).
Intuitively, this alteration should cause the compiler to do strictly more work
than the original benchmark, because now instead of being told what N to use
for each call, it needs to deduce the N. And because it needs to do a deduction
for each possible candidate, this should cause it to do an additional O(n) work
at compile time, uniformly across all of the different approaches. But compilers
are weird, and this “intuitive” hypothesis does not match our actual observations.
Whatever problem Cameron and Xiang Fan identified, it seems that in my translation into a new benchmark I must have reintroduced it, or a different problem, or worse.
Benchmark results
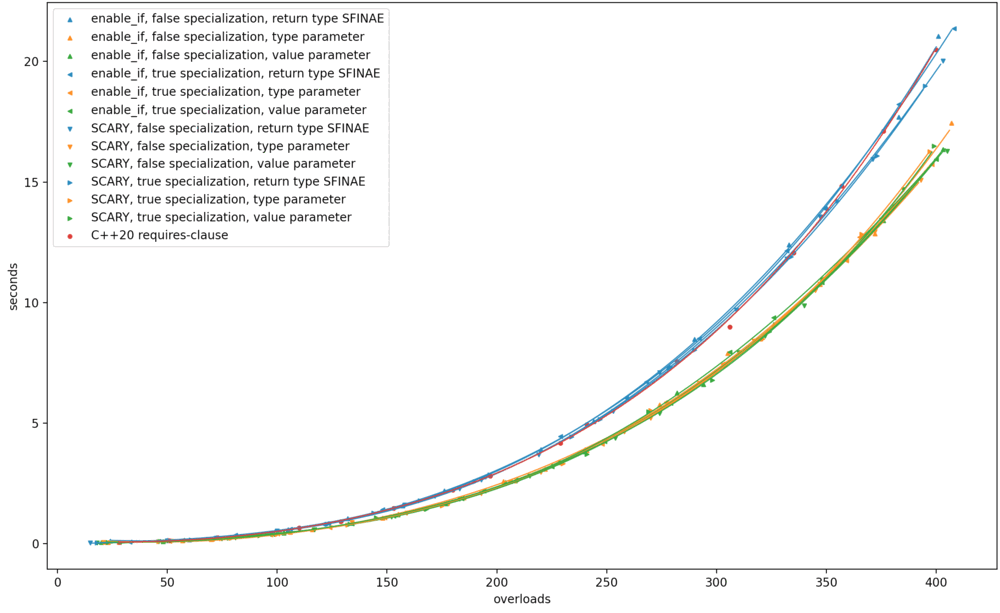
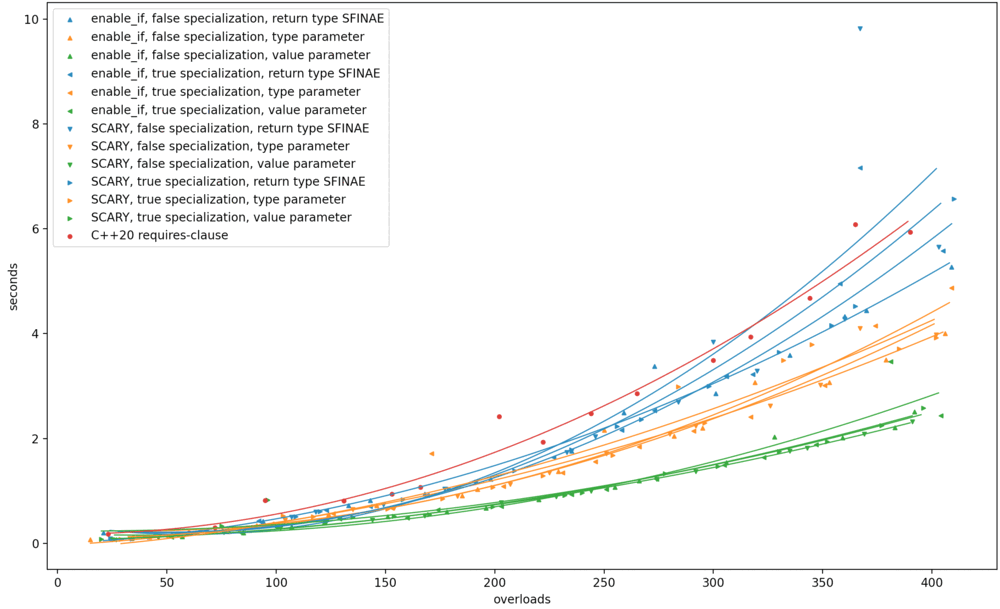
As before, I ran the benchmark on Clang trunk (the future Clang 14) on my MacBook; on GCC 10.3 on a shared Linux machine; and (via Nick Powell) on MSVC 19.30 on Windows. Here are the results. Original benchmark graphs on the left, new ones on the right.
f<K>(...) |
f(index_constant<K>{}, ...) |
|
|---|---|---|
| Clang 14 | 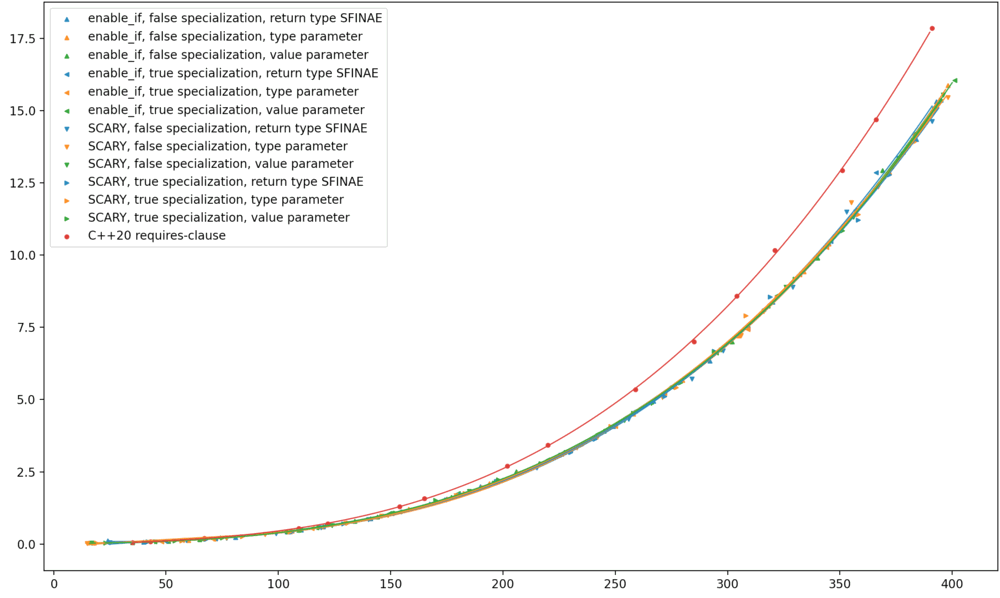 |
 |
| GCC 10 | 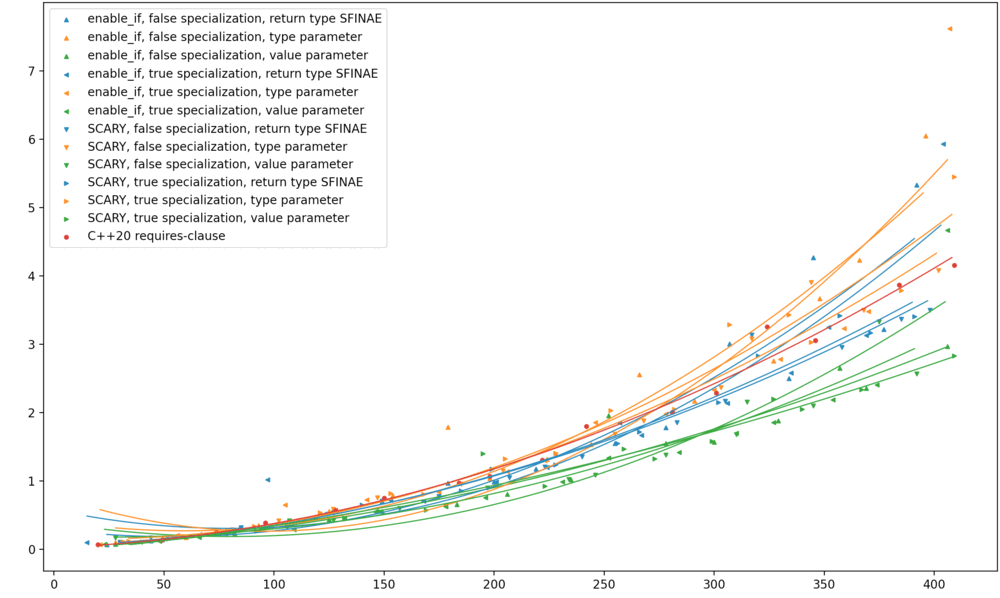 |
 |
| MSVC 19.30 | 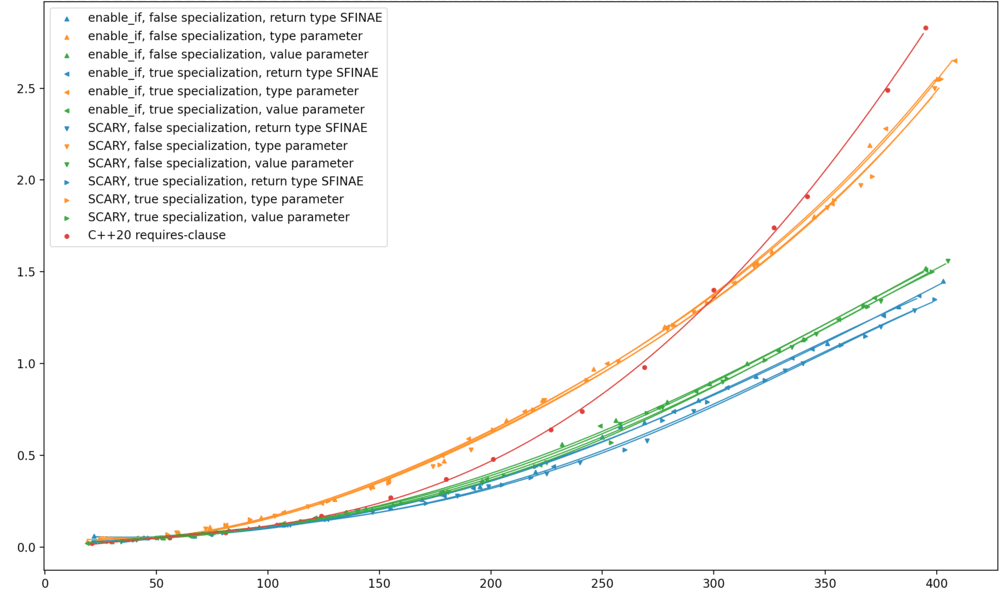 |
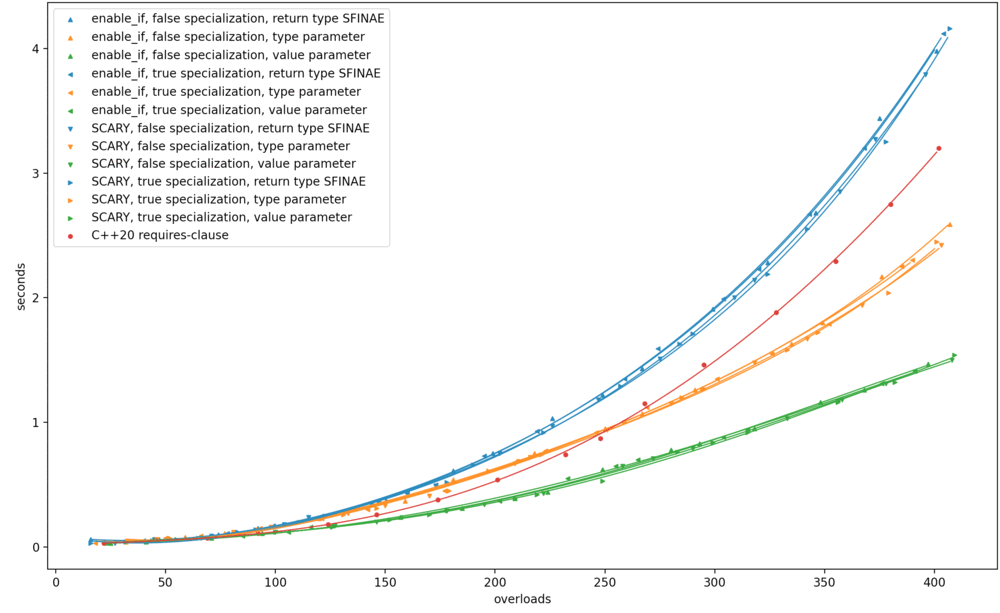 |
My observations are:
-
On Clang, this transformation somehow worsened the compile-time performance of return type SFINAE to match
requires, without changing anything else. -
On GCC, the results apparently became much more stratified, return type SFINAE worsened, and type-parameter SFINAE improved; but that might all be noise. I wouldn’t put stock in it.
-
On MSVC, return type SFINAE went from the best option to the absolute worst; and this change had no effect on the performance of
requires.
Across the board, return type SFINAE worsened. I see how return type SFINAE intuitively
does the most work before bailing out: If substitution failure happens while building the
template parameter list (value-parameter SFINAE), or while filling in the defaulted template
arguments (type-parameter SFINAE), that’s going to fail faster than if it happens while
building the function’s signature. But I can’t explain how return type SFINAE wasn’t already
the worst performer; why should deducing N matter so much to its performance alone?
As before, I should emphasize that these results pertain to a benchmark where
all it does is compute candidate sets, on overload sets with tens to hundreds of non-viable
candidates. Real-world C++ code doesn’t do this. (Code that uses << for output can definitely
run into hundred-candidate overload sets, but even there, we’re not eliminating them via SFINAE.)
To run the benchmark on your own machine, get my old Python script here and my new script here.